
Introducing EdgeRunner Tactical: A powerful and efficient language model for the edge
Our mission is to build Generative AI for the edge that is safe, secure, and transparent. To that end, the EdgeRunner team is proud to release EdgeRunner Tactical, the most powerful language model for its size to date.

EdgeRunner Tactical Unveiled
EdgeRunner Tactical is a 7 billion parameter language model that surpasses expectations for its size. This model delivers exceptional performance, showing that state-of-the-art (SOTA) capabilities can be achieved even within a compact architecture. With EdgeRunner Tactical, we are setting a new benchmark for open-source models, outshining competitors like Gemini Pro, Mixtral-8x7B, and Meta-Llama-3-8B-Instruct.
Key Features:
- 7 billion parameters that balance power and efficiency
- SOTA performance within the 7B model range
- Initialized from Qwen2-Instruct, leveraging prior advancements
- Self-Play Preference Optimization (SPPO) applied for continuous training and alignment
- Competitive performance on several benchmarks with Meta’s Llama-3-70B, Mixtral 8x7B, and Yi 34B
- Context length of 128K tokens, ideal for extensive conversations and large-scale text tasks
We’re proud to release EdgeRunner Tactical under an Apache 2.0 license, enabling unrestricted use and integration into various applications. Model card on Hugging Face is available here.
Training Method
We fine-tuned Qwen2-7B-Instruct using Self-Play Preference Optimization (SPPO), an algorithm designed to align language models with human preferences. SPPO formulates the alignment task as a two-player constant-sum game, where two instances of a language model play against each other. The primary objective is to find the Nash equilibrium policy, a strategy where each player optimizes their outcomes given the strategies of their opponents. In this context, the “game” involves consistently generating preferred responses, as evaluated by a preference model.
To approximate the Nash equilibrium policy, SPPO uses an iterative framework based on multiplicative weights updates. In each iteration, the policy is fine-tuned by playing against itself from the previous round, using synthetic data generated by the policy and annotated by the preference model. This is known as the “self-play” mechanism.
The SPPO loss function effectively increases the log-likelihood of the chosen response and decreases that of the rejected response, achieving an optimization that cannot be trivially obtained by symmetric pairwise loss methods like Direct Preference Optimization (DPO) and Identity Preference Optimization (IPO). For details, please see the SPPO paper.
Experiment
Similar to the SPPO paper, we utilize the PairRM model, an efficient pair-wise ranking preference model. Given two responses, y and y’, generated to an input prompt x, PairRM outputs a "relative reward" s(y, y’; x), which represents the strength difference between y and y′.
The experiments were conducted using 8 NVIDIA A100 GPUs. We carefully selected a subset from UltraChat (prompt only) and fully fine-tuned the Qwen2-7B-Instruct model using the SPPO loss.
We evaluated EdgeRunner Tactical across various benchmarks to ensure its generalist capabilities, including:
- MT-Bench
- Arena-Hard
- AlpacaEval 2.0
- GSM@ZeroEval
- MMLU-REDUX@ZeroEval
- WildBench
- Infinite Bench
MT-Bench
- EdgeRunner Tactical 7B: 8.55
- Qwen 7B Instruct: 8.41
Arena-Hard
|
Model |
Score |
CI |
Avg Tokens |
|
gpt-4-turbo-2024-04-09 |
82.63 |
(-1.71, +1.57) |
662.0 |
|
claude-3-5-sonnet-20240620 |
79.35 |
(-1.45, +2.06) |
567.0 |
|
gpt-4o-2024-05-13 |
79.21 |
(-1.50, +1.66) |
696.0 |
|
gpt-4-0125-preview |
77.96 |
(-2.12, +1.63) |
619.0 |
|
gpt-4o-mini |
74.94 |
(-2.40, +1.75) |
668.0 |
|
gemini-1.5-pro-api-0514 |
71.96 |
(-2.39, +2.10) |
676.0 |
|
yi-large-preview |
71.48 |
(-2.03, +3.14) |
720.0 |
|
claude-3-opus-20240229 |
60.36 |
(-2.84, +2.75) |
541.0 |
|
gemma-2-27b-it |
57.51 |
(-2.35, +2.46) |
577.0 |
|
gemini-1.5-flash-api-0514 |
49.61 |
(-2.93, +2.85) |
642.0 |
|
qwen2-72b-instruct |
46.86 |
(-2.51, +2.22) |
515.0 |
|
llama-3-70b-instruct |
46.57 |
(-2.00, +2.66) |
591.0 |
|
claude-3-haiku-20240307 |
41.47 |
(-2.15, +2.65) |
505.0 |
|
mistral-large-2402 |
37.71 |
(-1.88, +2.77) |
400.0 |
|
EdgeRunner-Tactical-7B |
37.47 |
(-2.74, +2.57) |
721.0 |
|
mixtral-8x22b-instruct-v0.1 |
36.36 |
(-2.61, +2.60) |
430.0 |
|
qwen1.5-72b-chat |
36.12 |
(-2.81, +2.39) |
474.0 |
|
phi-3-medium-4k-instruct |
33.37 |
(-2.02, +2.25) |
517.0 |
|
mistral-medium |
31.9 |
(-2.54, +2.13) |
485.0 |
|
phi-3-small-8k-instruct |
29.77 |
(-2.16, +2.02) |
568.0 |
|
mistral-next |
27.37 |
(-1.90, +1.99) |
297.0 |
|
qwen2-7b-instruct |
25.2 |
(-1.55, +2.46) |
618.0 |
|
gpt-3.5-turbo-0613 |
24.82 |
(-2.15, +1.90) |
401.0 |
|
claude-2.0 |
23.99 |
(-1.90, +1.75) |
295.0 |
|
Arcee-Spark |
23.52 |
(-2.03, +1.73) |
622.0 |
|
mixtral-8x7b-instruct-v0.1 |
23.4 |
(-1.87, +1.73) |
457.0 |
|
gpt-3.5-turbo-0125 |
23.34 |
(-1.46, +2.31) |
329.0 |
|
yi-34b-chat |
23.15 |
(-2.15, +1.85) |
611.0 |
|
starling-lm-7b-beta |
23.01 |
(-1.98, +1.71) |
530.0 |
|
claude-2.1 |
22.77 |
(-1.48, +2.38) |
290.0 |
|
llama-3-8b-instruct |
20.56 |
(-1.65, +2.09) |
585.0 |
|
gpt-3.5-turbo-1106 |
18.87 |
(-1.79, +2.34) |
285.0 |
|
gpt-3.5-turbo-0314 |
18.05 |
(-1.47, +2.09) |
334.0 |
|
gemini-pro |
17.8 |
(-1.65, +1.54) |
322.0 |
|
phi-3-mini-128k-instruct |
15.43 |
(-1.71, +1.60) |
609.0 |
|
mistral-7b-instruct |
12.57 |
(-1.58, +1.54) |
541.0 |
|
gemma-1.1-7b-it |
12.09 |
(-1.35, +1.56) |
341.0 |
|
llama-2-70b-chat |
11.55 |
(-1.18, +1.27) |
595.0 |
AlpacaEval 2.0
|
Model |
length_controlled_winrate |
win_rate |
n_total |
avg_length |
|
gpt-4o-2024-05-13 |
57.46 |
51.33 |
805 |
1873 |
|
gpt-4-turbo-2024-04-09 |
55.02 |
46.12 |
805 |
1802 |
|
claude-3-5-sonnet-20240620 |
52.37 |
40.56 |
805 |
1488 |
|
yi-large-preview |
51.89 |
57.47 |
805 |
2335 |
|
gpt4_1106_preview |
50.0 |
50.0 |
805 |
2049 |
|
Qwen1.5-110B-Chat |
43.91 |
33.78 |
805 |
1631 |
|
claude-3-opus-20240229 |
40.51 |
29.11 |
805 |
1388 |
|
gpt4 |
38.13 |
23.58 |
805 |
1365 |
|
Qwen1.5-72B-Chat |
36.57 |
26.5 |
805 |
1549 |
|
gpt4_0314 |
35.31 |
22.07 |
805 |
1371 |
|
Meta-Llama-3-70B-Instruct |
34.42 |
33.18 |
805 |
1919 |
|
EdgeRunner-Tactical-7B |
34.41 |
51.28 |
805 |
2735 |
|
mistral-large-2402 |
32.65 |
21.44 |
805 |
1362 |
|
Mixtral-8x22B-Instruct-v0.1 |
30.88 |
22.21 |
805 |
1445 |
|
gpt4_0613 |
30.18 |
15.76 |
805 |
1140 |
|
mistral-medium |
28.61 |
21.86 |
805 |
1500 |
|
claude-2 |
28.16 |
17.19 |
805 |
1069 |
|
internlm2-chat-20b-ExPO |
27.23 |
46.19 |
805 |
3335 |
|
Yi-34B-Chat |
27.19 |
29.66 |
805 |
2123 |
|
Starling-LM-7B-beta-ExPO |
26.41 |
29.6 |
805 |
2215 |
|
Llama-3.1-8B-Instruct |
26.41 |
30.32 |
805 |
2171 |
|
Snorkel-Mistral-PairRM-DPO |
26.39 |
30.22 |
804 |
2736 |
|
Arcee-Spark |
25.58 |
26.19 |
805 |
2002 |
|
claude-2.1 |
25.25 |
15.73 |
805 |
1096 |
|
gemini-pro |
24.38 |
18.18 |
805 |
1456 |
|
Qwen1.5-14B-Chat |
23.9 |
18.65 |
805 |
1607 |
|
Mixtral-8x7B-Instruct-v0.1 |
23.69 |
18.26 |
805 |
1465 |
|
Meta-Llama-3-8B-Instruct |
22.92 |
22.57 |
805 |
1899 |
|
gpt-3.5-turbo-0613 |
22.35 |
14.1 |
805 |
1331 |
|
Qwen2-7B-Instruct |
21.51 |
18.93 |
805 |
1793 |
|
gpt-3.5-turbo-1106 |
19.3 |
9.18 |
805 |
796 |
|
internlm2-chat-20b-ppo |
18.75 |
21.75 |
805 |
2373 |
|
claude-2.1_concise |
18.21 |
9.23 |
805 |
573 |
|
gpt-3.5-turbo-0301 |
18.09 |
9.62 |
805 |
827 |
|
deepseek-llm-67b-chat |
17.84 |
12.09 |
805 |
1151 |
|
vicuna-33b-v1.3 |
17.57 |
12.71 |
805 |
1479 |
|
Mistral-7B-Instruct-v0.2 |
17.11 |
14.72 |
805 |
1676 |
|
OpenHermes-2.5-Mistral-7B |
16.25 |
10.34 |
805 |
1107 |
|
Qwen1.5-7B-Chat |
14.75 |
11.77 |
805 |
1594 |
GSM@ZeroEval
|
Model |
Acc |
No answer |
Reason Lens |
|
Llama-3.1-405B-Instruct-Turbo |
95.91 |
0.08 |
365.07 |
|
claude-3-5-sonnet-20240620 |
95.6 |
0 |
465.19 |
|
claude-3-opus-20240229 |
95.6 |
0 |
410.62 |
|
gpt-4o-2024-05-13 |
95.38 |
0 |
479.98 |
|
gpt-4o-mini-2024-07-18 |
94.24 |
0 |
463.71 |
|
deepseek-chat |
93.93 |
0 |
495.52 |
|
gemini-1.5-pro |
93.4 |
0 |
389.17 |
|
Meta-Llama-3-70B-Instruct |
93.03 |
0 |
352.05 |
|
Qwen2-72B-Instruct |
92.65 |
0 |
375.96 |
|
claude-3-sonnet-20240229 |
91.51 |
0 |
762.69 |
|
gemini-1.5-flash |
91.36 |
0 |
344.61 |
|
gemma-2-27b-it@together |
90.22 |
0 |
364.68 |
|
claude-3-haiku-20240307 |
88.78 |
0 |
587.65 |
|
gemma-2-9b-it |
87.41 |
0 |
394.83 |
|
reka-core-20240501 |
87.41 |
0.08 |
414.7 |
|
Llama-3.1-8B-Instruct |
82.87 |
0.45 |
414.19 |
|
Mistral-Nemo-Instruct-2407 |
82.79 |
0 |
349.81 |
|
yi-large-preview |
82.64 |
0 |
514.25 |
|
EdgeRunner-Tactical-7B |
81.12 |
0.08 |
615.89 |
|
gpt-3.5-turbo-0125 |
80.36 |
0 |
350.97 |
|
command-r-plus |
80.14 |
0.08 |
294.08 |
|
Qwen2-7B-Instruct |
80.06 |
0 |
452.6 |
|
yi-large |
80.06 |
0 |
479.87 |
|
Yi-1.5-9B-Chat |
76.42 |
0.08 |
485.39 |
|
Phi-3-mini-4k-instruct |
75.51 |
0 |
462.53 |
|
reka-flash-20240226 |
74.68 |
0.45 |
460.06 |
|
Mixtral-8x7B-Instruct-v0.1 |
70.13 |
2.27 |
361.12 |
|
command-r |
52.99 |
0 |
294.43 |
|
Qwen2-1.5B-Instruct |
43.37 |
4.78 |
301.67 |
MMLU-REDUX@ZeroEval
|
Model |
Acc |
No answer |
Reason Lens |
|
gpt-4o-2024-05-13 |
88.01 |
0.14 |
629.79 |
|
claude-3-5-sonnet-20240620 |
86 |
0.18 |
907.1 |
|
Llama-3.1-405B-Instruct-Turbo |
85.64 |
0.76 |
449.71 |
|
gpt-4-turbo-2024-04-09 |
85.31 |
0.04 |
631.38 |
|
gemini-1.5-pro |
82.76 |
1.94 |
666.7 |
|
claude-3-opus-20240229 |
82.54 |
0.58 |
500.35 |
|
yi-large-preview |
82.15 |
0.14 |
982.6 |
|
gpt-4-0314 |
81.64 |
0.04 |
397.22 |
|
Qwen2-72B-Instruct |
81.61 |
0.29 |
486.41 |
|
gpt-4o-mini-2024-07-18 |
81.5 |
0.07 |
526 |
|
deepseek-chat |
80.81 |
0.11 |
691.91 |
|
Meta-Llama-3-70B-Instruct |
78.01 |
0.11 |
520.77 |
|
gemini-1.5-flash |
77.36 |
1.26 |
583.45 |
|
reka-core-20240501 |
76.42 |
0.76 |
701.67 |
|
gemma-2-27b-it@together |
75.67 |
0.61 |
446.51 |
|
claude-3-sonnet-20240229 |
74.87 |
0.07 |
671.75 |
|
gemma-2-9b-it@nvidia |
72.82 |
0.76 |
499 |
|
Yi-1.5-34B-Chat |
72.79 |
1.01 |
620.1 |
|
claude-3-haiku-20240307 |
72.32 |
0.04 |
644.59 |
|
Phi-3-mini-4k-instruct |
70.34 |
0.43 |
677.09 |
|
command-r-plus |
68.61 |
0 |
401.51 |
|
gpt-3.5-turbo-0125 |
68.36 |
0.04 |
357.92 |
|
EdgeRunner-Tactical-7B |
67.71 |
0.65 |
917.6 |
|
Llama-3.1-8B-Instruct |
67.13 |
3.38 |
399.54 |
|
Qwen2-7B-Instruct |
66.92 |
0.72 |
533.15 |
|
Mistral-Nemo-Instruct-2407 |
66.88 |
0.47 |
464.19 |
|
Yi-1.5-9B-Chat |
65.05 |
4.61 |
542.87 |
|
reka-flash-20240226 |
64.72 |
0.32 |
659.25 |
|
Mixtral-8x7B-Instruct-v0.1 |
63.17 |
5.51 |
324.31 |
|
Meta-Llama-3-8B-Instruct |
61.66 |
0.97 |
600.81 |
|
command-r |
61.12 |
0.04 |
382.23 |
|
Qwen2-1.5B-Instruct |
41.11 |
7.74 |
280.56 |
WildBench
|
Model |
WB_Elo |
RewardScore_Avg |
task_macro_reward.K=-1 |
Length |
|
gpt-4o-2024-05-13 |
1248.12 |
50.05 |
40.80 |
3723.52 |
|
claude-3-5-sonnet-20240620 |
1229.76 |
46.16 |
37.63 |
2911.85 |
|
gpt-4-turbo-2024-04-09 |
1225.29 |
46.19 |
37.17 |
3093.17 |
|
gpt-4-0125-preview |
1211.44 |
41.24 |
30.20 |
3335.64 |
|
gemini-1.5-pro |
1209.23 |
45.27 |
37.59 |
3247.97 |
|
yi-large-preview |
1209.00 |
46.92 |
38.54 |
3512.68 |
|
claude-3-opus-20240229 |
1206.56 |
37.03 |
22.35 |
2685.98 |
|
Meta-Llama-3-70B-Instruct |
1197.72 |
35.15 |
22.54 |
3046.64 |
|
gpt-4o-mini-2024-07-18 |
1192.43 |
28.57 |
0.00 |
3648.13 |
|
gemini-1.5-flash |
1190.30 |
37.45 |
26.04 |
3654.40 |
|
nemotron-4-340b-instruct |
1181.77 |
33.76 |
19.85 |
2754.01 |
|
deepseekv2-chat |
1178.76 |
30.41 |
12.60 |
2896.97 |
|
gemma-2-27b-it@together |
1178.34 |
24.27 |
0.00 |
2924.55 |
|
Qwen2-72B-Instruct |
1176.75 |
24.77 |
5.03 |
2856.45 |
|
reka-core-20240501 |
1173.85 |
31.48 |
17.06 |
2592.59 |
|
Mistral-Nemo-Instruct-2407 |
1165.29 |
22.19 |
0.00 |
3318.21 |
|
Yi-1.5-34B-Chat |
1163.69 |
30.83 |
16.06 |
3523.56 |
|
EdgeRunner-Tactical-7B |
1162.88 |
22.26 |
0.00 |
3754.66 |
|
claude-3-haiku-20240307 |
1160.56 |
16.30 |
-6.30 |
2601.03 |
|
mistral-large-2402 |
1159.72 |
13.27 |
-12.36 |
2514.98 |
|
deepseek-v2-coder-0628 |
1155.97 |
22.83 |
0.00 |
2580.18 |
|
gemma-2-9b-it |
1154.30 |
21.35 |
0.00 |
2802.89 |
|
Llama-3-8B-Magpie-Align-v0.1 |
1154.13 |
28.72 |
18.14 |
3107.77 |
|
command-r-plus |
1153.15 |
16.58 |
-3.60 |
3293.81 |
|
glm-4-9b-chat |
1152.68 |
20.71 |
2.33 |
3692.04 |
|
Qwen1.5-72B-Chat-greedy |
1151.97 |
20.83 |
1.72 |
2392.36 |
|
Yi-1.5-9B-Chat |
1151.43 |
21.80 |
4.93 |
3468.23 |
|
SELM-Llama-3-8B-Instruct-iter-3 |
1148.03 |
17.89 |
0.53 |
2913.15 |
|
Meta-Llama-3-8B-Instruct |
1140.76 |
6.72 |
-15.76 |
2975.19 |
|
Qwen2-7B-Instruct |
1137.66 |
16.20 |
0.00 |
3216.43 |
|
Starling-LM-7B-beta-ExPO |
1137.58 |
11.28 |
-9.01 |
2835.83 |
|
Hermes-2-Theta-Llama-3-8B |
1135.99 |
3.18 |
-23.28 |
2742.17 |
|
Llama-3.1-8B-Instruct |
1135.42 |
16.38 |
0.00 |
3750.60 |
|
reka-flash-20240226 |
1134.51 |
8.92 |
-12.52 |
2103.01 |
|
Mixtral-8x7B-Instruct-v0.1 |
1127.07 |
5.88 |
-19.71 |
2653.58 |
|
Starling-LM-7B-beta |
1122.26 |
7.53 |
-15.11 |
2797.81 |
|
command-r |
1122.25 |
4.28 |
-20.97 |
2919.42 |
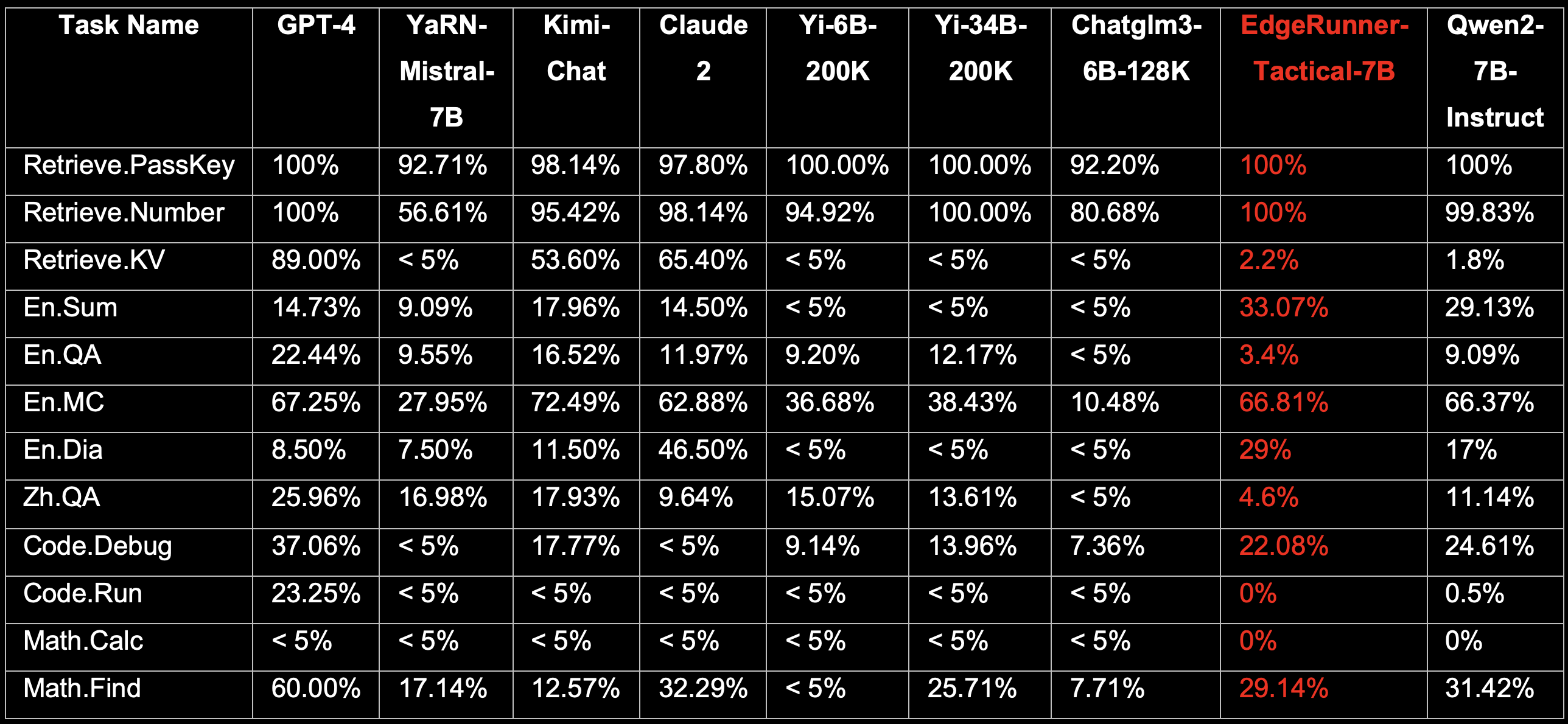
InfiniteBench
Potential Applications
The model's combination of small size and superior performance makes it suitable for:
- On-premise and edge computing
- Real-time applications like AI assistants, chatbots, and customer service automation
- Cost-effective AI implementation across organizations
Conclusion
We believe that Generative AI should be run locally and privately, whether on-prem, on-device, or inside your Virtual Private Cloud (VPC). As this technology becomes more powerful, it is imperative that enterprises and organizations own their AI and protect their sensitive information.
EdgeRunner Tactical demonstrates the power and capabilities of smaller models that can run locally at the edge. We are excited to share EdgeRunner Tactical with the community without restriction. Model card is available here.